
𝗠𝗼𝘃𝗲 𝗮𝗹𝗹 𝗠𝗮𝘁𝗵 𝘁𝗼 𝘁𝗵𝗲 (LLM)𝗢𝗦 𝗹𝗮𝘆𝗲𝗿!
Speak algorithms in natural language. Move from Algorithmic to Structured thinking.

With AI becoming more powerful and text based programming ubiquitous, we are steadily seeing a disruption where all the programming is achieved via natural language instructions, while the underneath (LLM) OS takes care of the optimization loop and the mathematical details.
Mathematical algorithms are at core of computer science, of computational work, but the rigid language of mathematics is a hindrance to democratization of computational work. The emerging models which work in text-mode (+visual + voice), have developed a rich understanding of mapping between natural language and algorithmic code. This opens up the floor to ordinary users to express even deeply algorithmic tasks, to a computer in a free-form language they both know very well.
So, users untrained in the math vocabulary can now instruct the AI with natural algorithmic tasks, and get them done. This is true even for complex tasks, without tinkering with a detailed, systematic mathematical formulation of the problem.
Even mathematicians and scientists would prefer to go up one level, delegate math-wrestling to the model, and work at a higher plane.
The math - a lot of it boils down to search for a solution(s) or optimization — can be delegated to the operating system (OS), the LLM OS.
This is in the sense of how humans interact with computers at present— users work at a higher level, unaware of many low-level supporting tasks that are taken care of by the commoditized OS.
The OS is decoupled from the users and is improved, scaled, monetized independently.
A fraction of human population has expertise in and builds, maintains improves this (LLM) OS.
Following the original article, many related projects have emerged. This section tracks some of the key developments that have arisen since then.
Oct ‘25. Training-free GRPO paper (Tencent). GRPO is a powerful RL optimization method, popularized by DeepSeek-R1. Instead of updating the policy weights from advantage computation on multiple/group samples, this paper uses LLM to summarize the rollouts, combine the summaries to create a lesson and then update the experience db using this lesson.
Oct’25 A distinct boundary between workers skilled in math vs LLM/Agents layer is now emerging. postSep’25. GEPA. article. GEPA (Genetic-Pareto) is a prompt optimizer that tackles this challenge by replacing sparse rewards (RL-style) with rich, natural language feedback. It leverages the fact that the entire execution of an AI system (including its reasoning steps, tool calls, and even error messages) can be serialized into text that an LLM can read and understand. GEPA’s methodology is built on three core pillars. GEPA is an instance of end-to-end natural language based learning - not the implicit weights, but the explicit orchestrator prompt program.
July 25. Arize AI. Prompt Learning:Using English Feedback to Optimize LLM Systems article. Update Prompt by NL feedback from individual runs. Full note here.
Each run is critiqued and correction feedback provided (human or LLM-edge)
Update the prompt judiciously to add the feedback
Compare to OPRO, where (output, feedback score) are added back as examples to prompt. Here, adding an utterance to the prompt, fixes the input, not output.
Compare to Dspy, where whole prompt is updated and there is fixed NL objective.
Here,
only instruction part of prompt is updated.
lazy objective: don’t need the final objective from start; keep adding objectives lazily as errors discovered on real runs. e.g., field ‘xyz’ is not there in JSOn, field ‘abs’ is not formatted correctly. Need a human for this ideally, because Judge LLM has a fixed objective.
How Prompt Edits/Updates can hurt (and so need a careful update operator)
updates add more run constraints/scenarios - enumerating scenarios bloats the prompt, makes them complex. (operator must compact periodically)
new constraints (refine older ones) cause ambiguity and confusion for LLM
older runs that were good, are now bad because older constraints were less strict
revisit and verify all the dev examples — may have to re-annotate
Very nice list of related papers in Appendix.
Here are a few examples to illustrate some of these emerging patterns.
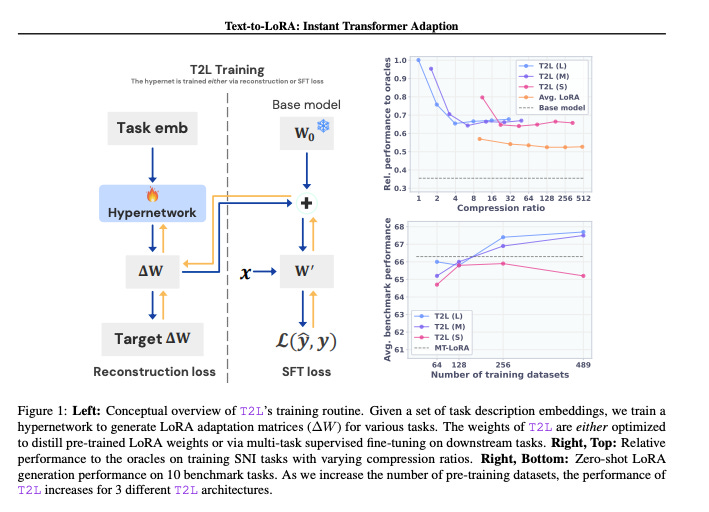
June 2025. Text-to-LoRA: Instant Transformer Adaption
Ever since large models took over, LoRA remains the goto technique to adapt LLMs for new tasks, by adding and training small neural modules, while keeping the original LLMs frozen.
Creating LoRA modules involves setting up the *right* configuration parameters and then baby-sitting the data/training to yield the desired outputs on the new tasks. Need new adapters for each task. Post-training, work is needed for loading/unloading and maintaining multiple such modules.
This is quite laborious and lot of engineering overhead for the team.
Instead, why not train a 'hyper-network' T2L that takes in text instructions for the new task and generates these adapters as outputs!
The paper shows this is not only feasible, but T2L zero-shot generalizes to entirely new tasks (based only on task text instructions)!
aside: this seems so close to in-context, prompt-based learning that I wonder if we really need explicit adapters anymore?
Read the paper here.
June 2025. Autotrain-MCP
This is an MCP server for training AI models, so you can use your AI tools to train your AI models 🤯.
Space: https://huggingface.co/spaces/burtenshaw/autotrain-mcp
Use this MCP server with tools like Claude Desktop, Cursor, VSCode, ChatGPT, or Continue to do this:
- Define an ML problem like Image Classification, LLM fine-tuning, Text Classification, etc.
- Claude Desktop etc. can retrieve models and datasets from the hub using the hub MCP.
- Training happens on a Hugging Face space, so no worries about hardware restraints.
- Models are pushed to the hub to be used inference tools like Llama.cpp, vLLM, MLX, etc.
- Built on top of the AutoTrain library, so it has full integration with transformers and other libraries.
A lot of mathematical optimization has already been abstracted to structured configuration files. It only remains for human to provide the specific parameter values for the algorithm to boot up, execute and get the task done. and unsurprisingly, it is quick and easy for human to communicate those values in natural language.
While the LLMOS guys continue to iterate the configuration interface, and improve the underneath setup and execution, the rest of the world can train complex AI models, and in general, do complex computational tasks, by expressing themselves naturally.
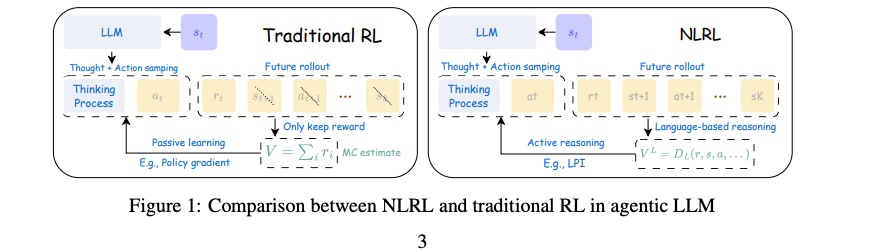
Nov 2024. Natural Language Reinforcement Learning
Natural Language RL innovatively redefines RL principles, including task objectives, policy, value function, Bellman equation, and policy iteration, into their language counterparts.
Query: You are the player 'O' in tic-tac-toe. Given current board state, what's your next move to win?
Response:
- Thought: 'O' should block 'X'
- Action:
Embed optimizer components into natural language!The individual steps of the algorithm are specified in English, with mathematical translation left to the underlying LLM.
" ... aims to train an LLM critic capable of evaluating any given state with natural language explanations, similar to a chess annotator who provides insightful commentary on boards, moves, and strategies."“In this work, we propose a new paradigm NLRL, which reformulates the RL process with natural language representation. We believe NLRL opens a new door for understanding and implementing RL algorithms in natural language space, improving agent’s effectiveness, efficiency and enabling active learning. NLRL also serves as a potential way for generating high-quality language synthetic data for policy and critic, which could be crucial in training more advanced language models and agents.”
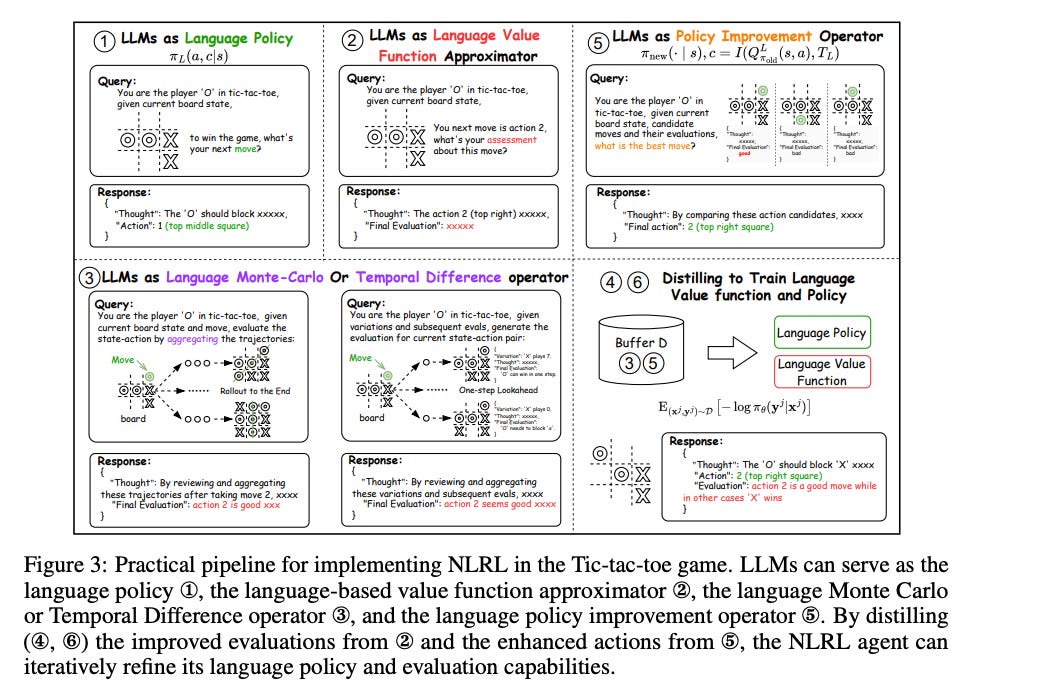
Find the paper here.
Structured Thinking sits on top of Algorithmic Thinking
In summary, humans can now afford to move up from low-level algorithmic thinking (or, writing code) to higher-level structured thinking (or, writing markdown). Even for tasks that are considered deeply algorithmic or mathematical.
The mathematical / algorithmic thinking is taken over by the internals of the (LLM)OS, with text-based tasks mapped to internal representation of, say, the Transformer model.
Structured thinking has its own challenges, humans need training to do it well.
Because the models are evolving, there will be a constant back-and-forth between structured and algorithmic thinking and writing.
More updates coming soon!
This is a fluid post and I’ll be adding more.
Subscribe to stay in touch with the updates.