
RAG++ : Bridge the Query - Doc Gap
(LLM-IR #2) How I stopped viewing RAG as a laundry list of tricks

You have heard and read all about RAG. It is tempting to believe that we can chunk up the doc and match each chunk with query (with embeddings) and find the relevant doc chunks. Unluckily, the simplistic chunk-embed-match method falls short when put into action. To fulfill the promise, a plethora of advanced techniques have emerged. Complex RAG diagrams like the one below.
RAG is now a complex beast in your head. We ask: need it be so?
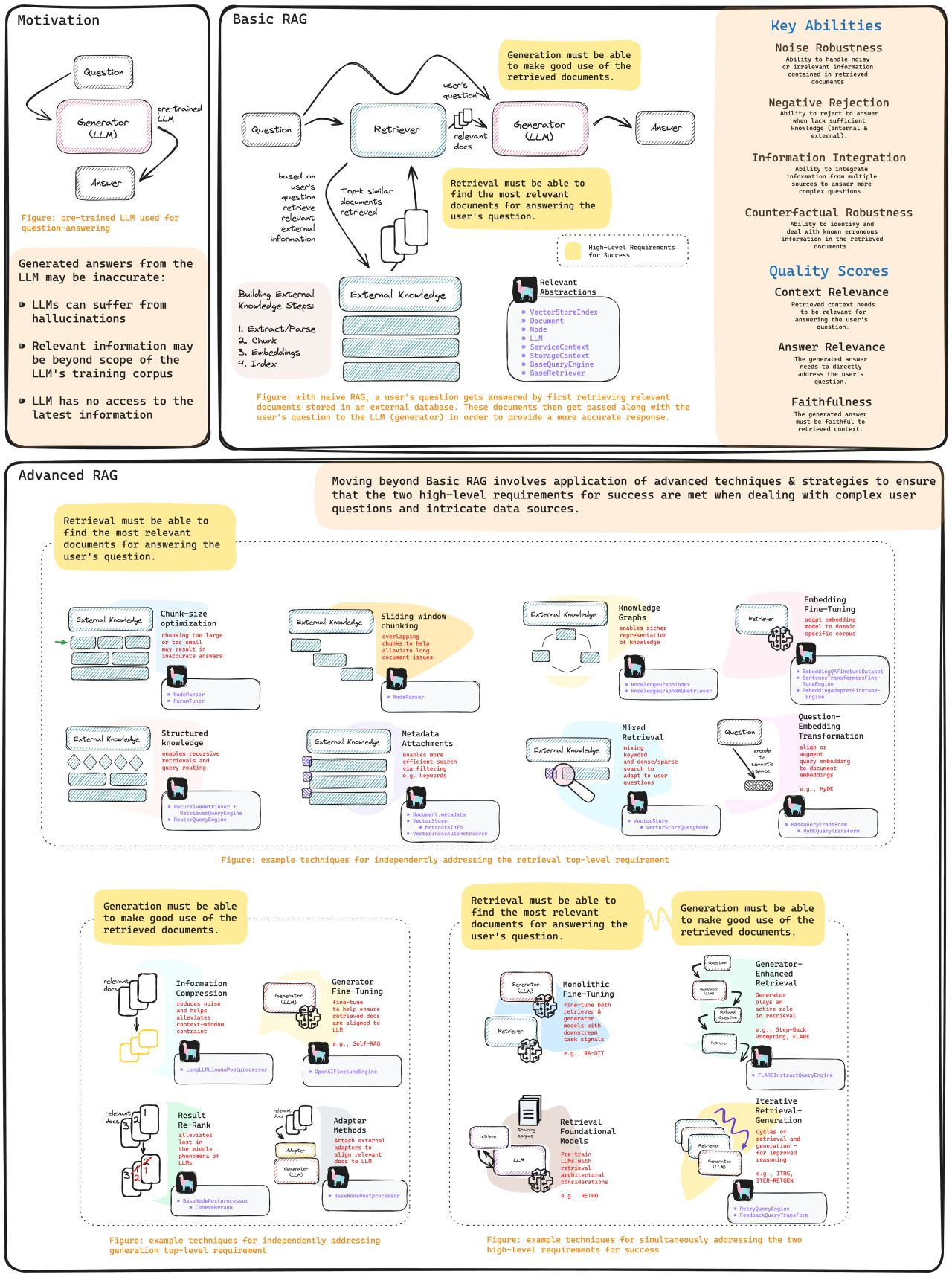

In this article, we rethink and present a fresh take on RAG that simplifies the complex RAG landscape that currently exists. Building upon the ideas of representation nodes and query-doc bridges, the new framework greatly simplifies how we problem solve and apply RAG in practice.
Quick Overview
Why does naive RAG fail? First because question and answer are entities of different types; they are duals. For example, a question like "Why is the sky blue?" and its answer, "The scattering of sunlight causes the blue color" have distinctly different linguistic forms. Naive embedding-similarity may not be able to bridge them.
Second, the information that a query seeks may not entirely lie with a single or contiguous document snippets; it is often spread across several descriptive and metadata document components. How do we seamlessly bridge the query to several heterogeneous document parts?
Instead of chunk-embed-match, it is useful to think of retrieval/ranking as trying to bridge the gap between the query and relevant document snippets. By directing our efforts towards finding efficient bridging strategies, we prioritize the information the query is seeking from the docs, freeing us from getting caught up in less important tasks like chunking.
What is a bridge? How do we bridge?
Explain step-by-step.
First, we introduce the idea of representation nodes (rep nodes). Rep nodes are alternate representations of a text snippet, e.g., a rewrite, a summary, structured data, or a vector embedding.
Reframe the process of retrieving and ranking documents for a query as bridging the gap between the query and the document using rep nodes.
Bridging involves finding shortest paths in the graph of rep nodes between query and the document repository.
Show how a dozen of advanced upcoming RAG methods are understood easily in this framework.
Bridging Query and Doc: a quick example
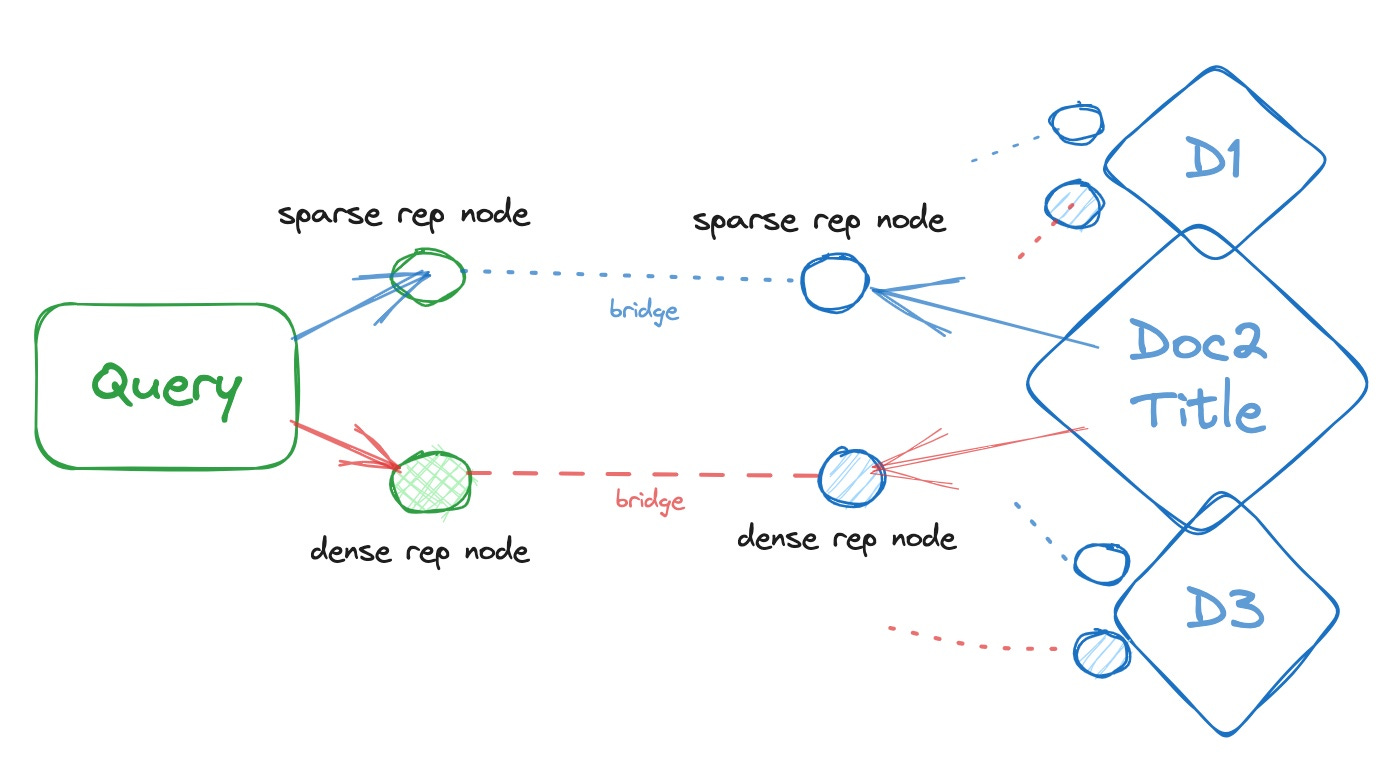
Consider a simple retrieval setting to find relevant docs by matching query with the doc titles only: embed query, embed doc title, match (cosine similarity) and rank by similarity scores. However, we need to decide which embedding model to use :
do we need an exact keyword match between query and doc title?
query: 64.2 inch console table | doctitle: decor 64.2'' console tabledo we need to match the meaning of query and doc?
query: kitchen table with a thick board | doctitle: industrial solid wood dining table
Depending on the kind of match we seek, we rely on different embedding models - sparse for exact match, dense for semantic match. In some cases, we need both.
Bridging for retrieval?
Create sparse and dense rep nodes for both query and doc titles, and bridge the rep nodes (cosine similarity).
Each such rep node bridge leads to a path from query to doc, which has a numeric score.
We find the most relevant docs by finding the top few shortest paths (path length = score) from query to docs.
In some cases, multiple paths (sparse and dense rep node paths) may exist and should be fused. We discuss this later.
Generalize a bit:
to bridge, create intermediate representations (call them rep nodes), which are easier to bridge / known ways to bridge.
in graph terms, bridging creates paths between query and docs via rep nodes. the shortest paths lead to most relevant docs.
rank by k-shortest paths to get the final result list. In practice, we think of results as a ranked list of documents -- this is equivalent to ordering documents by their mathematical distance to the query (k-shortest paths).
we have a wide range of options available for creating rep nodes, both for query and docs. The choice of rep nodes is crucial to the success of your RAG setup and requires careful consideration.

Bridging with Rep Nodes for Nested Documents
The popular method to chunk documents small, embed and match is also a bridging strategy: we bridge query rep to each chunk rep and find the shortest distance chunks. For many reasons, this technique is limited (yet quite popular): chunks have no context, how small or big do you chunk a doc, regular/irregular sizes and so on.
Given a repository of nested documents, let us explore a more powerful bridging strategy.
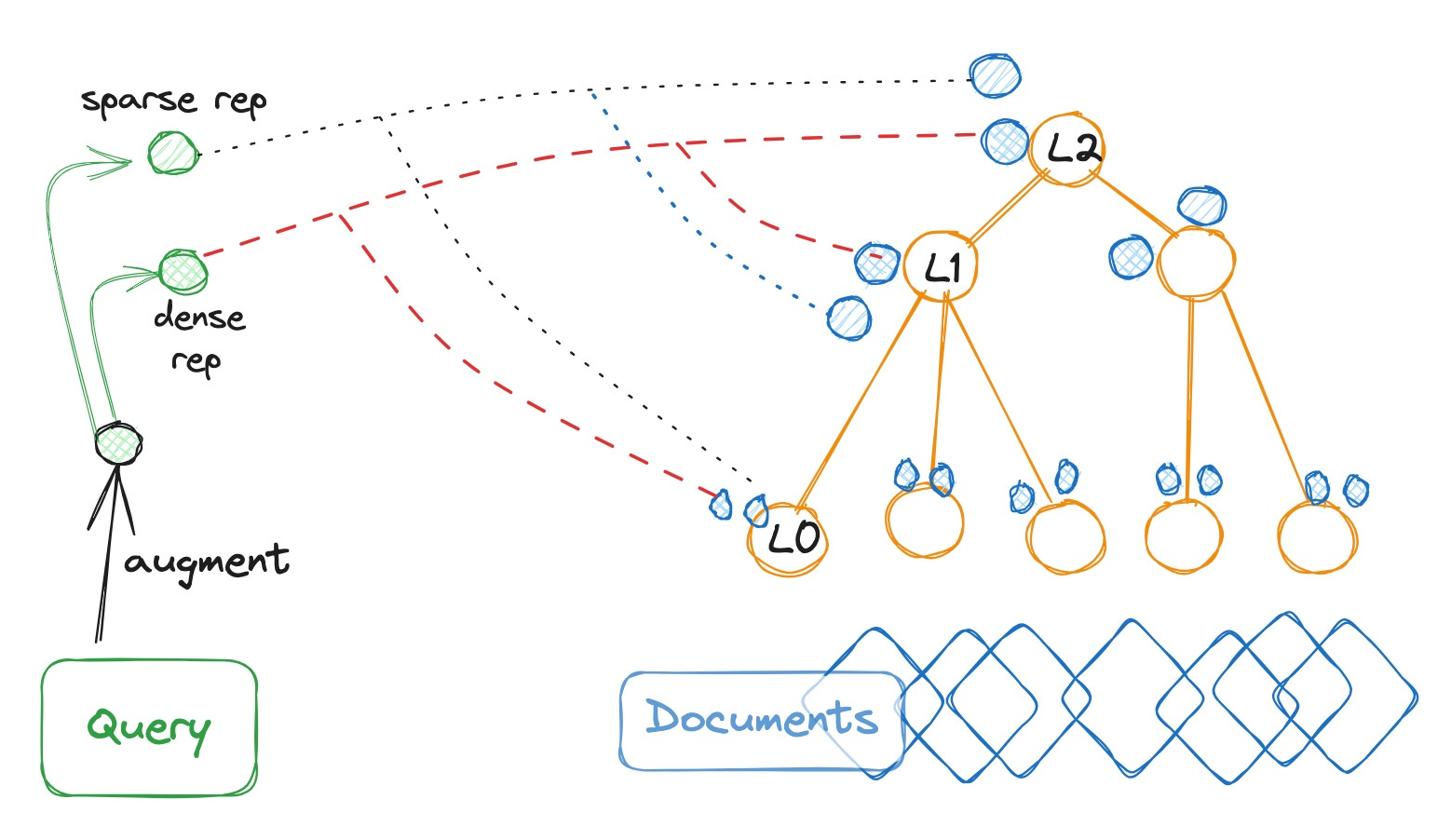
Each document has a natural hierarchy of sections, sub-sections and so on. (Levels L2, L1, L0 in the diagram above)
create summary rep nodes at each document level (orange) by summarizing the doc content at that level (recursively if needed).
summaries help determine if any part of the doc below is relevant to the query.
embed these summaries as sparse and dense vectors (blue rep nodes for each orange node).
Augment the query (e.g. make it less ambiguous or rewrite it) -> black rep node. Then create two rep nodes (green) for the augmented query (sparse and dense vector rep).
Now try to bridge the query reps with doc reps
start from a query rep node
find the k-nearest (most similar, shortest vector distance) Level:N summary rep nodes. call them candidate nodes. prune away rest Level:N nodes
obtain the Level:N-1 children of candidate nodes. Repeat 2 until find the best Level 0 nodes or another termination criteria.
Once we've created a hierarchy of rep nodes over the document repository, we can fall back upon conventional shortest path search procedures over graphs. In essence, by creating these intermediate rep nodes between query and docs, we now have an efficient divide-conquer strategy to find the relevant doc snippets across large, nested doc repositories.
Besides the summary rep nodes, there are many different clever choices for creating rep nodes, which we can use to solve practical RAG problems.
Bridging Strategies
A broad variety of retrieval, ranking techniques may be viewed as query-doc bridging over different kinds of rep nodes. Let us see some examples.
Query Rewriting as Bridging
Query rewriting or augmentation transforms original user query into an alternative query that bridges to the documents better
query expansion. add terms (synonyms, antonyms) or phrases that overlap with desired documents
query rephrase (change term order, linguistic transforms) to make it less ambiguous, includes context and closer to specific set of documents.
query -> query-augment rep -> query-vector rep.
A form of query augmentation is to create hypothetical documents (hy-docs) for a query. These hy-docs help bridge to real docs more easily. For example, the Hyde method, implementation in LangChain.
Multiple key reps for query. A single vector rep for a query may not be enough to bridge to the relevant documents. For example, the sparse vector rep for query will bridge to doc snippets with exact word matches while the dense vector rep will bridge to doc snippets with similar semantic meaning as query. Depending on the use case, we may prefer one over other or a combination.
multiple rep nodes: query -> sparse-vec rep, query -> dense-vec rep, ...
find shortest path for each query rep and aggregate them (see rank fusion below)
Query decomposition. Some parts of a query may match with doc snippets, while other parts match with doc metadata. Hence transform query into sub-queries.
split query into a combination of text rep and metadata rep nodes. Bridge each rep to doc separately. See Langchain self-querying and LlamaIndex auto-retriever.
split query into a sequence of text queries. Bridge each sub-query to doc, in sequence. See Multi-hop RAG, Sub-question query engine.
Optimize over chunk sizes. We don't know apriori if the query seeks information at sentence or paragraph or section level. So, setup all possible doc rep nodes at different levels (split doc into multiple chunk sizes), and find shortest paths from query rep node to all these doc rep nodes. Here the value nodes are text snippets and key nodes are the vector reps of them. However, this method relies on making good manual chunk size guesses (and comes across as overly brute-force).
Summary rep nodes. Compute summary (aggregate information using fewer tokens) for each doc snippet (as in diagram above). Instead of using original doc snippets to compute vector reps directly, add an extra rep layer of summaries.
Intuitively, the value nodes are summaries, and keys are summary vector reps.
Bridge summary vector reps with query vector reps.
Benefit+: final results may include shorter summaries instead of original doc snippet.
Benefit++: summaries can bridge across data types and modes. For example, RecursiveRetriever in LLamaIndex bridges across text summary rep and tabular data rep.
Question rep nodes. What questions can a doc snippet answer? Each question becomes a doc rep node. Bridge query reps with question vector reps.
Metadata rep nodes. Many docs have a natural hierarchy: section, sub-section, paragraphs, and so on. Make a 'section title' a key rep node which links with each of 'subsection title' value rep nodes. These rep nodes easiest to obtain: we need to only (!) parse the document structure correctly.
Context window rep nodes. Instead of following the natural doc hierarchy, we can create a key rep node to be a larger, contiguous doc snippet window around the original doc snippet value. These larger context windows help in providing more information to the later step result aggregator. For example, see LlamaIndex's decoupling chunks for retrieval vs synthesis.
Key-Value chains One can view a doc rep node at level k as a key, for level k-1 doc rep node value. So, in effect, we try to build shortest paths over rep nodes (key-value chains) from query to doc.
Retrieval and Ranking is all about
setting up the right intermediate rep nodes (for both query and docs)
an efficient strategy to find shortest paths from query rep nodes to doc rep nodes.
fusing multiple candidate paths between query and docs.
By strategically transforming the query and doc representations, we are able to reach intermediate bridge nodes, where we can cross over and find relevant items on the other side.
The bridging strategies we’ve described above form the bag-of-tricks at our disposal to attack new RAG problems.
Fusing shortest paths
Path Fusion. Once you find top-k shortest paths from query reps to doc reps, there is still a lot of redundancy.
Both query rep
qr1andqr2reach the same doc repdrvia multiple paths with different distancesv1andv2. what's the actual distance todr?A popular way is fuse paths is by ranking
drfor each rep type and then combining the ranks. For example, see Reciprocal Rank Fusion.
Dominators. Multiple nearest doc reps dr1_k , dr2_k , ... at level k are children to the same doc rep dr_{k-1} at level k-1, i.e., dr_{k-1} dominates dr?_k (see Dominator(graphs))
Instead of including a long list of dr?_k in the final results, include only dr_{k-1}, reducing the redundancy in results. For example, Langchain's ParentDocRetriever and LlamaIndex's automerging retrieval.
Other Business/Desirability Objectives. Once k-shortest path documents have been selected, their final rank (how they are presented to the user) may be determined by completely different objectives - popularity, price, click rate, and so on. Practical systems are often two -hase: first recall relevant documents, then rank by objectives.
Path ahead
When targeting a new RAG problem, ask the following questions:
what does an efficient bridging strategy look like?
how to augment the query? what different rep nodes to create for this query?
which rep nodes to create for docs? how to exploit doc hierarchy?
how to find shortest paths efficiently? filter out irrelevant keys, fuse multiple paths to same doc snippets.
Use LLMs to solve RAG sub-problems.
creating hierarchical summaries may not be the best idea. As Raptor shows, it is smarter to cluster intermediate nodes by their information content, even across section boundaries
Rep nodes can be created dynamically. For example, by querying a table during search.
how do we use LLM to create the rep nodes? (query rewriting, understanding, doc summaries)
how do we use LLMs to find or fuse shortest paths (rank docs)?
resolving queries involves finding the right doc snippets and then extracting the desired information from them. LLMs for the final extraction?
Recap
This article reinterprets the common wisdom (and advanced RAG methods) in terms of a more intuitive model of bridging the query and doc snippets. By directing our efforts towards finding efficient bridging strategies, we prioritize hunting for the information that the query seeks from the docs, and avoid getting caught up with distractors like optimizing chunk size.
Setting up an efficient strategy requires you to think carefully about what intermediate rep nodes should be created and how to efficiently scan and prune the huge number of rep nodes. All you need is a rep node planner!
LLMs play an important role in this bridging process: rewriting queries, summarizing and extracting answers from doc snippets, aggregating / ranking doc snippet results.
Read More
(LLM-IR #1) Why your GPT + Vector Search demo won't make it to production?