


(LLM-IR #1) Why your GPT + Vector Search RAG demo won't make it to production?
On the perils of the naive embed-match strategy

One of the most popular use cases made feasible by ChatGPT / OpenAI APIs is the ability to chat with custom documents, company web pages, video transcripts and so on. Here is how the popular embed-and-match recipe works:
Collect (Scrape) the full set of documents and split documents into chunks.
Embed each of these chunks into a vector using an neural text encoder E (SentenceBERT, OpenAI embeddings, …)
Store the embedding vectors in a Vector Database (Pinecone, Weaviate, Qdrant, Milvus, Faiss, Postgres, Supabase, …)
When user fires a natural language query q, embed q with the encoder E and ask the Vector DB to find K similar vectors
Map the similar vectors back to the documents D
Present the documents D to GPT large language model (LLM) and prompt it to create a coherent response based on D, which answers the query q.
The steps in the recipe above (barring the last one) instantiate what is known as the Information Retrieval (IR) flow. Then, a large model (LLM) is assisted by this IR flow (Retrieval Augmented LLMs) to answer user queries in a conversational format. We may call the overall technique as Retrieval Augmented Generation or Generative IR.
UPDATE: Check out the new lean, flexible framework, Ragpipe, we are building to enable you to iterate fast on your RAG flows and extract desired insights from your document repositories.
Social media now has tons of demos / repos / videos, with different levels of sophistication, showing how to tackle this use case and chat seamlessly with documents. So, what’s the problem? Consider, for example, this query on r/LangChain, snapshotted below. Although the LangChain library empowers you to quickly build sophisticated Vector DB indices over many document types, query over the indices in natural language and ask OpenAI GPT seamlessly, it doesn’t guarantee search quality.
Our user is tired and unhappy, wondering what will improve the search results. The responses are all over the place — modify the query, a query expansion trick, better prompts with chat history, or try a different Vector DB. Also, the conversation quickly switches to how to pick among the many Vector DBs, which is far from the real issue.
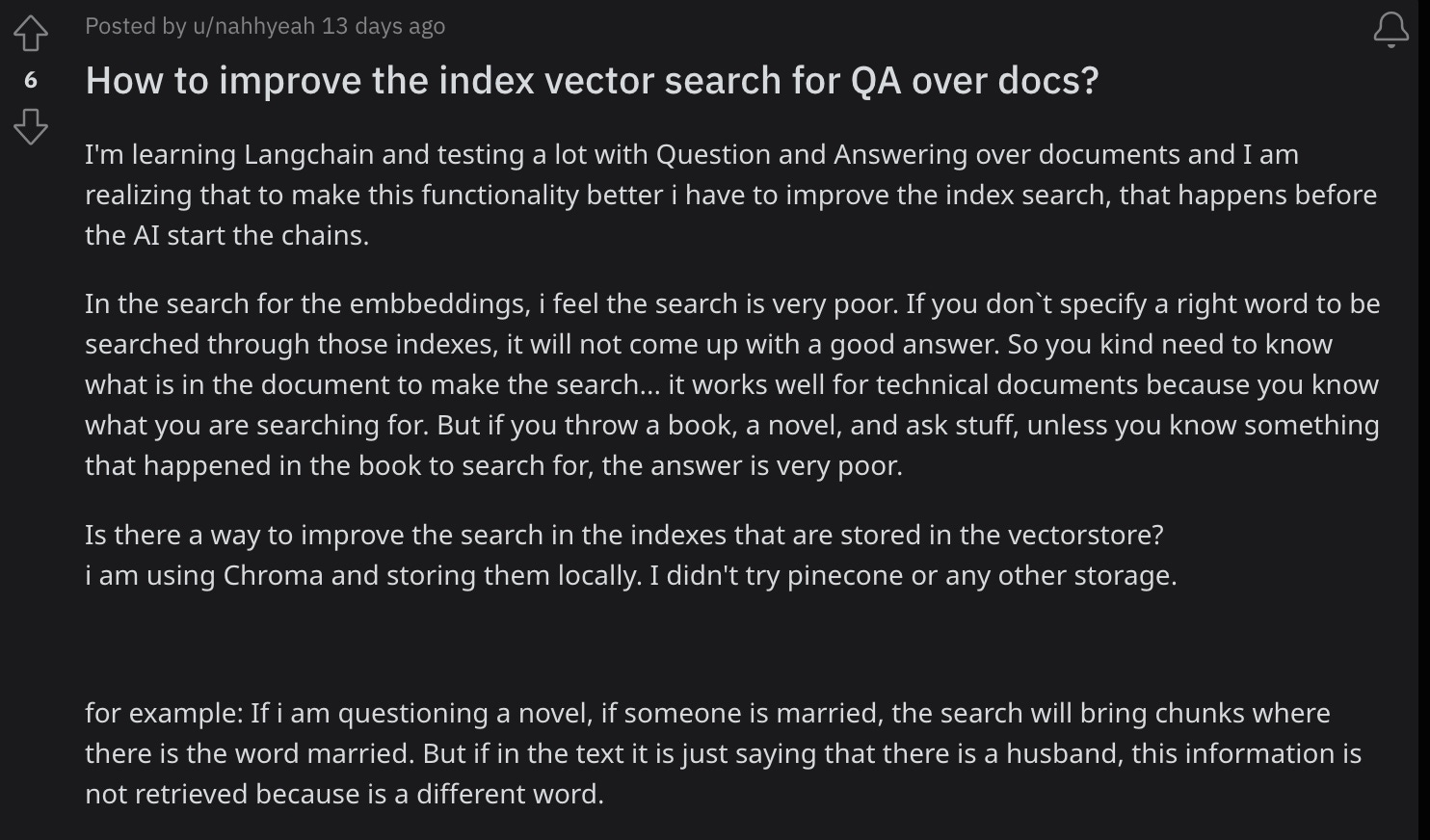
The trouble is that most demos show cherry-picked results, ask easy questions, do not extend the conversation, and rarely talk about the failure cases. Thankfully, some articles do talk about the doc chunking tradeoffs, unreliability of GPT when presented with irrelevant snippets and other issues, which indicate that solving this problem is far from trivial.
To understand why, let’s step back a bit. Information Retrieval (IR) is a decades-old field that focuses on the process of obtaining relevant information from large collections of data and seeks to efficiently relate a query with documents that answer it. IR involves techniques and algorithms for searching, ranking, and presenting information to users to satisfy their information needs. IR has gone through stages of transformations, starting from early keyword based and probabilistic methods to Machine Learning (ML) and Deep Learning (DL) based sophisticated techniques.
Both the syntax (keywords) and semantics (meaning) of the query and documents play an important role in finding a good match. The Vector databases (popularized in the recipe above) consolidate the DL solutions built over the last decade.
IR+GPT is easy!
To the naive eye, the recipe above seems to be an easy hack to solve the IR problem over an ocean of complex documents. It is tempting to ask what’s the big deal about IR then. In that vein, let us try to solve IR from first principles.
Solution 1: simply look for documents with words in the query (lexical matching) and weigh them by frequency?
⚠️ But then you learn that words have different forms (match, matcher, matching), words mean differently in different contexts (river bank vs financial bank), some words are all over the place (the, all, in, ..) but irrelevant.
⚠️ How do you handle words never seen before?
⚠️ Word string matches aren’t good enough; how do we match sentence spans with similar meaning ?
Solution 2: how about embedding words (or even sentences or paragraphs) as vectors and matching ? This approach shields you from word forms, and even spelling errors. Plus it enables semantic matching across sentences, with unrelated words but similar meaning.
⚠️ But then questions of granularity come in. Embed words or sub-words or characters or .. ? How best to embed bigger chunks - sentences or paragraphs? How big should the doc chunks be for precise semantic matches?
⚠️ How do you handle words never seen before?
⚠️ Then, a deeper problem: does this semantic embedding-match strategy equate with the notion of similarity in the user’s mind?
⚠️ and finally, semantic matches are never enough. You also need the exact (keyword, lexical) matches, which is tricky for the semantic vector engine.

So, should we combine these two lexical and semantic match strategies? How? Many more questions follow:
Will those off-the-shelf embeddings work well for my queries?
Should we match embeddings precisely or quantize them for approximate, fast search? Single or multi-vector indices? (see article)
What about matching real documents which have text and other structured and nested fields? What strategy will handle these docs effectively?
How do you avoid near-duplicates in the search result?
Do this at scale of billion documents? Make the user happy without letting costs spiral out of control?
As you encounter these roadblocks and overcome one hurdle after another, you gradually get drawn into the rabbit hole that IR is. You begin to appreciate (obsessing over?) how hard it is to tackle the apparently simple query - docs matching problem.
IR: a quick overview
To get a glimpse into the complexities of real-life IR pipeline, please read my short note on the core elements of IR here.
tldr: when a user fires a query, the goal is to retrieve all the relevant documents (Recall), but only the relevant ones (Precision). How do this efficiently?
First, filter candidates from the ocean of documents (Candidate Generation) with fast-light methods
Then use more complex techniques to rank the candidate list (Ranking).
Unified view, the first stage does a low-cost-accuracy ranking and the second stage does a high-cost-accuracy (re-)ranking of results from the first stage.
Try hard to guess user’s real intent and ensure the final results make them happy.
Oh wait. But that’s just the IR part. The GPT / LLM is unreliable in its own ways:
you must prompt it hard to stick to the documents you provided in its response and not tap into its huge, memorized, fast, random-access information store.
if the prompt is imperfect, the LLM may not find an answer.
make sure that the context documents you provided are very relevant to the query (see recall and precision above), else the LLM is not to blame for attending to the irrelevant parts of the context and crafting a willy-nilly response.
Larger document chunks do not ensure better results with LLMs.
In Summary
Building useful chat products that can converse with heterogeneous documents is far more complex than following the embed-and-match recipe and then presenting the retrieved documents as context to LLMs. There are several sources of complexity:
The IR pipeline is complex. Capturing relevance of a documents vs a query, by embedding query and documents as sparse or dense vectors, is too simplistic.
Real-life documents are not just text. They are a mix of text and structures (fields, tables). Flat embeddings of hierarchical documents do not capture nuanced query-doc similarity. (more in the next post)
The LLM is unreliable. It can choose to ignore the context docs or attend to the wrong parts or hallucinate.
In the next article, I’ll go down this rabbit hole some more. I will discuss how we can engineer such Generative IR systems effectively to yield responses that satisfy users.
I hope this series leaves you more informed, particularly, if you are committed to the long road on using IR + LLMs to build useful products.
Here’s the follow up article.
(LLM-IR #2) RAG from Scratch: Bridging the Query - Doc gap
Read more.
[LLM #1] The Emergence of Conversational Programming
[LLM #2] The Trust Tug-of-War with GPT